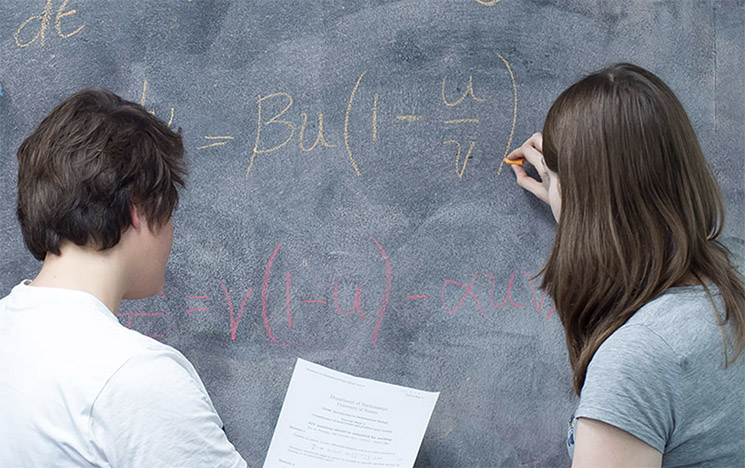
Your future career
What to do with a Mathematics degree.
Unlock the power of mathematics. Graduate with the analytical and industry-standard tools to take your career in any direction you choose.

At Sussex, you’ll learn from experts involved in real-world research. This includes a diverse range of areas in applied and pure mathematics, including:
You’ll develop analytical and modelling skills and use industry-standard software (such as Python, MATLAB, SAS and R). Our links with graduate employers will help you meet potential employers and secure placements. You’ll graduate with the knowledge to take your career in any direction you choose.
Hi, I'm Jess, and I study Maths with Finance at the University of Sussex.
A bit about me is that I used to play county hockey and I'm working towards Grade Eight in piano.
I'm going to talk about my university experience and why I chose Sussex.
So I must've gone and visited over ten other unis before I found Sussex but I just feel like it has the best of everything, has the countryside, the city, Brighton Beach, which is obviously a plus and the campus feel was really nice as well, especially when moving away from home for the first time, it felt really kind of welcoming and like little community within the big city.
The Maths School was really good as well on the Open Day.
I remember I had a really, really interesting lecture and I noticed there were loads of like social spaces within the Maths School where students would get together.
I thought it was really nice.
So starting university in Covid I didn't really know what to expect.
My lectures happened to all be online, but my seminars in person were really good and I managed to meet a lot of my course mates that way.
I also joined hockey, which was a really fun society, and I've been playing for the seconds team this year.
At Freshers Fair, I joined Ultimate Frisbee, Pole Fitness, Hockey and the Surf Society.
And we even went on a trip to Newquay to surf in October.
That was really good.
I think a few of my favourite things that happened this year is kind of without COVID, the Maths School been really open and buzzing.
There are always my course mates around to help me with worksheets.
So making use of the social spaces and my student rep is really good at organising things like meals out and quizzes for everyone.
Since coming to Sussex, I've definitely become more confident.
I'll actually ask the staff for help, you know, put my hands up in lectures.
I definitely was too scared to do that at the beginning.
Everyone in the Maths department is really friendly, always willing to help, always around if you need them.
I've also learned so many new things like surfing.
Learnt how to play ultimate Frisbee.
That has been really fun.
I'm looking forward to next year when I get to pick some of my modules, so I don't know what I want to do yet.
So I think there's a module called Maths in Biology, which I'm really interested in, I'd love to find out a bit more about that and kind of see what area I might want to go in in the future- what job I might want.
I had to look at over ten different universities before I found Sussex.
It's definitely the place for me but you'll find the university for you and I hope that's Sussex.
What to do with a Mathematics degree.
Mathematics research at Sussex.
Dr Omar Lakkis teamed up with environmental advice company Ambiental to refine a maths equation that calculates flood risks.
How mathematics is helping to feed the growing global population.
Could there be a better place to be a student than our beautiful campus? Nestled in the South Downs National Park, we’re just nine minutes from one of the UK’s most iconic cities.
To get a picture of life on our campus and the excitement of being in the city of Brighton, take our virtual tour.
Find out more about fees, funding and student budgeting.
Uncover everything that Brighton has to offer – our city by the sea.
Take a look at our accommodation options, both on and off campus.





