Unbounded Activity Discovery
Lifelearn: Unbounded activity and context awareness
Lifelearn aims to automatically discover new activities beyond a pre-defined set of trained activities by exploiting assumptions about human behaviour and new time series clustering techniques. Once new activities are discovered they are modelled and eventually their semantic meaning can be uncovered through additional data sources or involvement of the user.
Applications find themselves in scenarios of high societal value, such as the realisation of automatic life logs, which could serves as a "memory prosthesis" for people with dementia or allow to insert cues in everyday life to support desired behaviour change.
Current methods can only recognise pre-defined or "closed sets" set of activities and context. However, this is insufficient for real-life usage. In numerous applications, the set of relevant activities is not necessarily known at design-time, as different users tend to have different routines, routines may change as users change interests, and activities may be performed differently, for instance after an injury. Therefore the set of relevant activities and contexts is potentially unbounded and is said to be "open-ended".
Unbounded, Open-ended Activity Recognition (OpenAR) is a step closer to real-life activity recognition. OpenAR should dynamically adapt and should be able to recognize new situations and new behaviours (not previously included in the initiation period, i.e., training data).
The project investigates the methods required to recognise an "open-ended" set of activities and contexts from existing wearables, such as a smartwatch and a mobile phone, following lifelong learning principles. In other words, the system should discover that a user engages in a new activity, even if it was not initially programmed with the knowledge of that activity.
UnADevs Method
To tackle this problem, we propose the UnADevs method (Unbounded Unsupervised Activity Discovery using the Temporal Behaviour Assumption). In particular the method is based on online clustering, and additinally includes the temporal information of the occuring activities. Therefore, it is able to discover clusters of repating/periodic activities as the occur and additionally keeps track of the time interval of the discovered cluster. This way, the system may prompt the user about the discovered activity with the appropriate time interval and ask for feedback. The following example shows an acceleration signal of 4 repetitive/periodic activities (sitting, jogging, shovelling, and walking). The UnADevs method finds the 4 clusters of activity segments, and potetnially can prompt the user to label them.

UnADevs is an online method (it clusters streams of data in real time) and is based on the online agglomerative clustering method (http://gromgull.net/blog/2009/08/online-clustering-in-python/). UnADevs improves upon by introducing a mechanism to exploit the temporal assumption of continuity of human behaviour. The temporal assumption is motivated by the following: (i) data points should be close both in time and feature space; (ii) the time may help distinguishing activities which are close in feature space. This is illustrated with the following example of 3 activities and 2 features. On the left, including the temporal component heps us to distinguish the 3 activities, which is difficult by using only the 2 features.
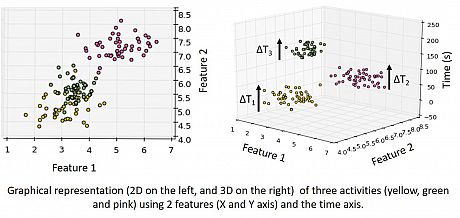
UnADevs has 3 mechanisms (controlled by 3 algorithm parameters) to handle the temporal dependence of the data:
- First, at any point in time, the method keeps a pool of active clusters, so that multiple deviations can be clustered into multiple temporally overlapping clusters. These clusters would effectively be distinct in terms of their class centres but potentially overlapping in time. The activePool parameter defines this number of clusters in the pool of active clusters. Note that this is not the total number of clusters (which is open ended).
- Second, each active cluster has some waiting period (tolerance) in which it stays active and can be updated. This way it better handles short outliers (such as brief deviations from the nominal behaviour) without creating a separate cluster for each deviation. Basically, the tolerance parameter defines the duration a cluster is allowed to remain in the pool of active clusters without being updated. A larger value allows to tolerate more outliers or transients before deciding to "freeze" the cluster which means deciding that a cluster segment has been discovered. A smaller value would decrease the tolerance to noise and may increase the number of discovered clusters.
- Finally, the method has a minimum duration parameter (minDur) which is the minimum duration that a cluster must reach, otherwise the cluster is discarded. In this way, the method discards the potential small cluster segments that are found for each short deviation. Chiefly, if we are interested in discovering activities lasting at least N seconds then minDur is set to N.
Evaluation
We evaluated the method on 2 established HAR dataset:
- The first dataset is the Jozef Stefan Institute – Activities of Daily Living (JSI-ADL) dataset (H. Gjoreski et al. “Context-based ensemble method for human energy expenditure estimation” ). It was chosen because it contains activities of daily living (walking, lying, sitting, cycling, etc.), and also includes some more complex repetitive activities such as: shovelling, scrubbing the floor, washing dishes and working on PC.
- The second dataset is the REALDISP HAR dataset (Damas et al. "A benchmark dataset to evaluate sensor displacement in activity recognition"). It contains 34 (33 + NULL) fitness activities performed by 17 subjects. It contains data logged from 9 inertial sensors sampled at 50 Hz, from which we have chosen the left wrist accelerometer because of practical reasons (smartwatch).
Results
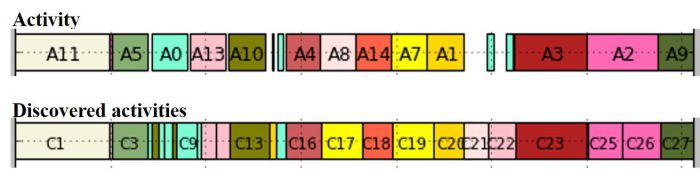
The figure below illustrates the activity discovery results for Subject 1. It shows at the top the 14 activity segments annotated in the dataset, each marked with its class number (the smaller clusters are not marked for space reasons, and some activities repeat such as A0). Underneath, the figure shows the cluster segments identified by the 5 methods each marked with a number and a colour. The cluster segment numbers are always incrementing for our method, Baseline-T and DBSCAN-T, and for the Baseline and DBSCAN the same cluster can repeat in multiple segments. The colour of the clusters corresponds to the colour of the activity whose centre is the closest in the feature space. The empty space between the activities are the NULL segments.
 JSI-ADL activity identification results for Subject 1. Activity segments are at the top, identified clusters by each method are below
JSI-ADL activity identification results for Subject 1. Activity segments are at the top, identified clusters by each method are below
The Figure below shows the results for the unsupervised evaluation. Our method performs significantly better in all of the metrics compared to the Baseline and DBSCAN. The accuracy, the F-1 score and the activity detection ratio are similar to the Baseline-T and DBSCAN-T, however our method achieves a significantly better fragmentation, while maintaining discovery of 83% of the 180 activity segments.
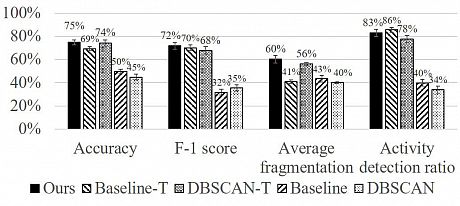 JSI-ADL unsupervised activity discovery comparison of the 5 methods using the 4 evaluation metrics
JSI-ADL unsupervised activity discovery comparison of the 5 methods using the 4 evaluation metrics
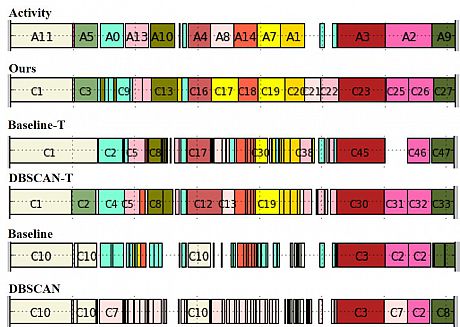
The figure below presents the detailed results for Subject 1 for the REALDISP dataset. The top row shows the 33 activities (two of which repeat, resulting in 35 activity segments. Similar to the results of the previous dataset, the Baseline and DBSCAN methods appear to highly fragment the activity segments. We again speculate that this is because they do not use the temporal information about the data windows. DBSCAN-T and Baseline-T perform better, but both fail to identify significant number of activities: they identified only 15 and 20 out of the 35 activity segments, respectively, while our proposed method identified 31. In general, our method better identifies (matches) the activities, both in the matching colour and the number of activities found.
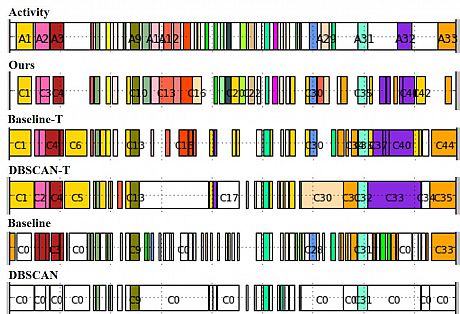 REALDISP activity identification results for Subject 1. Activity segments are at the top, clusters by each method are below
REALDISP activity identification results for Subject 1. Activity segments are at the top, clusters by each method are below
The figure below shows the unsupervised evaluation (ignoring the cluster colours). Our method has similar accuracy compared to Baseline-T, and slightly worse fragmentation, but performs significantly better on all the other metrics. The activity detection ratio of our method is significantly higher than the Baseline-T. Our method was able to discover 87% of the activities, i.e., it found 467 out of the total 537 activity segments over all 17 users.
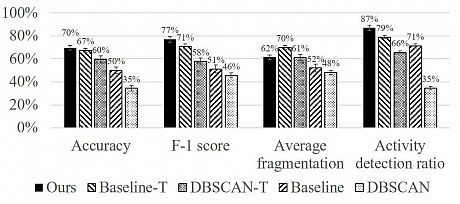 REALDISP activity discovery comparison of the 5 methods using 4 evaluation metrics
REALDISP activity discovery comparison of the 5 methods using 4 evaluation metrics
To the best of our knowledge, this is the first approach to activity discovery in an online setting, and that has been evaluated on two HAR datasets containing large number of activities (14 and 33 respectively). The evaluation showed that it achieved better and sometimes worse but similar performance compared to the competing approaches, and has managed to discover 616 of the total 717 activities.
UnADevs is memory and time efficient because it is online and does not keep all the samples in memory, but instead processes them one by one, keeping only aggregates in memory (cluster centre, cluster duration, cluster size). This makes UnADevs suitable for embedded and real-time implementations on microcontrollers.
One limitation of the proposed is that reoccurring activities lead each time to a new cluster segment. We envision a further extension which compares the newly found cluster segment to the list of all previously identified cluster segments and finds and regroups the most similar clusters.
Since the features are one of the most important step in the clustering and machine learning in general, we are planning to tackle this problem with Deep Learning. In particular, we plan to use CNNs and Autoencoders in order to learn rich general representations/features which can enable a wider range of activity discovery, compared to engineered features.
Code and Publication
The main publication about the UnADevs method is:
- Hristijan Gjoreski, Daniel Roggen. Unsupervised Online Activity Discovery Using Temporal Behaviour Assumption. In: 21th International Symposiumon Wearable Computers (ISWC) 2017, 11-15 September 2017, Maui, Hawaii, USA.
The algorithm code and example evaluation is available at: https://github.com/sussexwearlab/OpenEnded
Related Publications
- Hristijan Gjoreski, Daniel Roggen. Unsupervised Online Activity Discovery Using Temporal Behaviour Assumption. In: 21th International Symposiumon Wearable Computers (ISWC) 2017, 11-15 September 2017, Maui, Hawaii, USA.
- Kawaguchi, Nobuo, Nishio, Nobuhiko, Roggen, Daniel, Inoue, Sozo, Pirttikangas, Susanna and Van Laerhoven, Kristof (2016) 4th Workshop on human activity sensing corpus and applications: towards open-ended context awareness. In: Ubicomp workshop, 12-16 September 2016, Heidelberg, Germany.
- Ciliberto, Mathias, Ordonez Morales, Francisco Javier and Roggen, Daniel (2016) Exploring human activity annotation using a privacy preserving 3D Model. In: HASCA Workshop at Ubicomp, 12-16 September 2016, Heidelberg, Germany.
- Ordonez Morales, Francisco Javier and Roggen, Daniel (2016) Deep convolutional and LSTM recurrent neural networks for multimodal wearable activity recognition. Sensors, 16 (1). pp. 1-25. ISSN 1424-8220
- Ordonez Morales, Francisco Javier and Roggen, Daniel (2016) Deep convolutional feature transfer across mobile activity recognition domains, sensor modalities and locations. In: 20th International Symposiumon Wearable Computers (ISWC) 2016, 12-16 September 2016, Heidelberg, Germany.
People
Dr Hristijan Gjoreski; Dr Francisco Javier Ordonez Morales, Mathias Ciliberto, project supervised by Dr Daniel Roggen
Acknowledgements
EPSRC project "Lifelearn: Unbounded activity and context awareness" EP/N007816/1
