Projects
Our research is currently focussed on three areas:
- The predictive brain
Although we may not be aware of it, the information conveyed by our senses is incomplete and ambiguous. Because of natural variability in the way we speak, one person’s “s” might sound identical to another person’s “sh”, especially in the background noise of modern-day environments. How are we able to perceive speech despite sensory ambiguity?
Many believe that the answer to this question is provided by a theory known as predictive processing. According to this theory, the brain is constantly predicting what is going to happen next and uses those predictions to fundamentally shape what is perceived. For example, after hearing the speech sounds “l-a-v-i”, it is proposed that listeners strongly predict “sh” because lavish is a rather more frequent word than Lavis (an area in northern Italy). This ability to form predictions would be enormously beneficial for perception, ensuring “lavish” is correctly identified even in a noisy room.
In one line of work, we are building computer models (simulations) of speech predictive processing. These models recreate what we think might be happening in the brain when we listen to speech. We then correlate these models with recorded brain activity from human volunteers. If these models accurately explain what is happening in the brain, then they should correlate well with observed brain activity. By constructing different models in this fashion, we are testing ongoing controversies concerning the neural basis of predictive processing.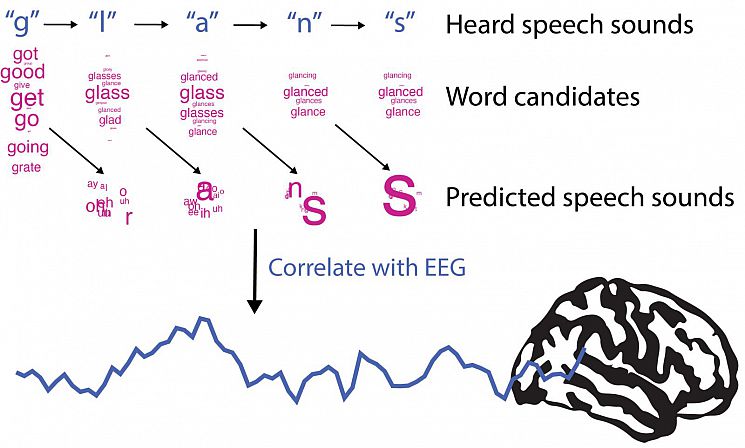 lllustration of predictive processing model for the example word "glance". After hearing the first speech sound "g", there are many possible word candidates ("get", "good" etc.) and so there are many predictions for what speech sound might be heard next. By the end of the word, there are only a few possible word candidates that match what has been heard, which generates fewer (and stronger) predictions. If this is a good model of human speech processing, it should correlate closely with EEG recordings of brain activity from human volunteers listening to speech.
lllustration of predictive processing model for the example word "glance". After hearing the first speech sound "g", there are many possible word candidates ("get", "good" etc.) and so there are many predictions for what speech sound might be heard next. By the end of the word, there are only a few possible word candidates that match what has been heard, which generates fewer (and stronger) predictions. If this is a good model of human speech processing, it should correlate closely with EEG recordings of brain activity from human volunteers listening to speech. - Perceptual learning
For many deaf listeners, the cochlear implant is a life changing device. In directly stimulating auditory nerve fibres, cochlear implants restore the sense of sound. Yet the sounds conveyed by an implant are highly degraded – and unnatural – in comparison with a healthy ear. The extent of this degradation becomes apparent when listeners who could hear before their deafness are asked to describe what speech sounds like after implantation (examples are “Robotic” and “Mickey mouse”). After implantation, listeners must therefore learn to interpret degraded speech, a gradual process known as perceptual learning. Remarkably, many listeners learn well enough that they can understand speech using only sound from the implant, without lipreading. How does the brain learn to adapt its knowledge of speech to make sense of novel, highly degraded sounds?
In our lab, we address this question with normal hearing listeners by deliberately degrading speech to simulate the sounds provided by an implant. With training, listeners improve their ability to understand degraded speech. By using behavioural tests and recordings of brain activity, we are investigating how training changes listeners' perception of degraded speech.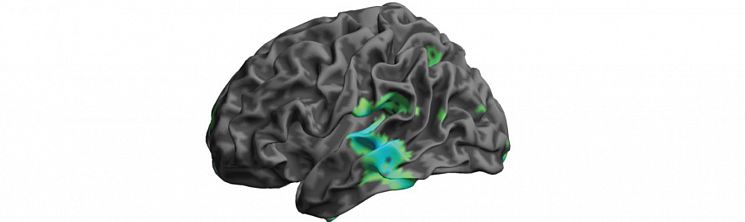 Perceptual learning changes brain responses in the superior temporal gyrus, a region involved in auditory and speech processing. Data recorded using magnetoencephalography (MEG), from Sohoglu and Davis (2016 PNAS).
Perceptual learning changes brain responses in the superior temporal gyrus, a region involved in auditory and speech processing. Data recorded using magnetoencephalography (MEG), from Sohoglu and Davis (2016 PNAS). - Individual differences in speech perception ability
While difficulty understanding speech in background noise is a common complaint in older adults, previous studies show that even young adults with normal hearing vary widely in their ability to understand noisy speech. We are investigating the reasons for this by measuring speech-in-noise performance in different listeners. By correlating performance with a range of other perceptual and cognitive tasks, we can address whether individual differences in speech-in-noise perception are related to general cognitive faculties (e.g. working memory, attention) or more specific perceptual processes (e.g. predictive speech processing).